


正则表达式 - 教程
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字>母)和特殊字符(称为"元字符")。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
正则表达式是繁琐的,但它是强大的,学会之后的应用会让你除了提高效率外,会给你带来绝对的>成就感。只要认真阅读本教程,加上应用的时候进行一定的参考,掌握正则表达式不是问题。
许多程序设计语言都支持利用正则表达式进行字符串操作。
基本语法
| 字符 | 描述 |
|---|---|
| [ABC] | 匹配 [...] 中的所有字符,例如 [aeiou] 匹配字符串 "google runoob taobao" 中所有的 e o u a 字母。![[ABC].jpg](https://snowlove.synology.me:5106/usr/uploads/2021/05/331281439.jpg) |
| 1 | 匹配除了 [...] 中字符的所有字符,例如 2 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字母。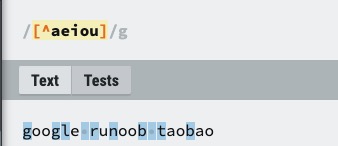 1.jpg" title="1.jpg"> 1.jpg" title="1.jpg"> |
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。![[A-Z].jpg](https://snowlove.synology.me:5106/usr/uploads/2021/05/2883772674.jpg) |
| [\s\S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。![[sS].jpg](https://snowlove.synology.me:5106/usr/uploads/2021/05/306372584.jpg) |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
| . | 匹配除换行符 \n 之外的任何单字符 |
| l | 逻辑或操作符 |
| - | 定义一个区间 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\' 匹配 "\",而 '(' 则匹配 "("。 |
| * | 匹配前面的字符或者子表达式0次或多次 |
| + | 匹配前一个字符或子表达式一次或多次 |
| *? | 惰性匹配上一个 |
| +? | 惰性匹配上一个 |
| {n,}? | 前一个的惰性匹配 |
| ? | 匹配前一个字符或子表达式0次或1次重复 |
| {n} | 匹配前一个字符或子表达式 |
| {m,n} | 匹配前一个字符或子表达式至少m次至多n次 |
| {n,} | 匹配前一个字符或者子表达式至少n次 |
| \c | 匹配一个控制字符 |
| \d | 匹配任意数字 |
| \D | 匹配数字以外的字符 |
| \t | 匹配制表符 |
| \w | 匹配任意数字字母下划线 |
| \W | 不匹配数字字母下划线 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
正则表达式
(?:pattern)、(?=pattern)、(?!pattern)、(?<=pattern)和(?<!pattern)
| 字符 | 描述 |
|---|---|
| ?: | exp1(?:exp2):全局只会查找一次exp2 |
| ?= | exp1(?=exp2):查找 exp2 前面的 exp1。.jpg") |
| ?<= | (?<=exp2)exp1:查找 exp2 后面的 exp1。.jpg") |
| ?! | exp1(?!exp2):查找后面不是 exp2 的 exp1。.jpg") |
| ?<! | (?<!exp2)exp1:查找前面不是 exp2 的 exp1。.jpg") |
正则常用方法
正则中有常用的六种方法;分为两类,一类是:RegExp对象方法;一类是:支持正则表达式的String对象的方法。
- 一、RegExp对象方法(两个):exce()和test()
语法:RegExpObject.exec(string)
c1.1. exce()方法
介绍:
exec() 方法用于检索字符串中的正则表达式的匹配,如果字符串中有匹配的值返回该匹配值构成的数组 ,且该数组还有继承的属性:
index:表示第一个匹配的字符在原字符串中的位置,
input:表示原字符串,groups:表示当初中命名的分组时匹配到的分组对象;
exec()方法没有匹配到数据时返回 null。
当正则匹配中没有分组时:
var str="Hello45647 123 world!Hello 1423 world! ssfsdf";
var patt2=/(?<hello>\d)+/;
var result2=patt2.exec(str);
console.log(result2)
当正则匹配中有分组且分组存在名字时:
var str="Hello45647 123 world!Hello 1423 world! ssfsdf";
var patt2=/(?<hello>\d)+/;
var result2=patt2.exec(str);
console.log(result2)
没有匹配到符合正则的字符时:
var str="Hello world!Hello world! ssfsdf";
var patt1=/\d+/;
var result1=patt1.exec(str);
console.log(result1)//null1.2、test()方法
介绍:
方法用于检测一个字符串是否匹配某个模式;如果字符串中有匹配的值返回 true ,否则返回 false。
var str="Hello world!";
//查找"Hello"
var patt1=/Hello/g;
var result1=patt1.test(str);
console.log(result1); //true
//查找 "Runoob"
var patt2=/Runoob/g;
var result2=patt2.test(str);
console.log(result2); //false支持正则表达式的String对象的方法:search()、replace()、split()、match()
语法:string.search(RegExpObject)
2.1、search()方法
简介:
用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。
如果找到任何匹配的子串,则返回 该子串在原字符串中的第一次出现的位置。
如果没有找到任何匹配的子串,则返回 -1。
var str1 = 'hello 123 world 456';
var reg1 = /\d+/;
console.log(str1.search(reg1));//6
console.log(str1.search("world"));//10
var str2 = 'hello world';
var reg2 = /\d+/;
console.log(str2.search(reg2));//-1
console.log(str2.search("nihao"));//-12.2、replace()方法
简介:
用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。原字符串不变,创建一个新的字符串
创建一个新的字符串,原字符串不变
var str="hello world! hello world! hello world!";
var n=str.replace('hello',"Runoob");
console.log(str)
console.log(n)
替换第一个和替换全部符合正则的子串
var str="hello world! hello world! hello world!";
var a=str.replace(/hello/,"Runoob");
var b=str.replace(/hello/g,"Runoob");
console.log(a)
console.log(b)
2.3、split()方法
简介:
用于把一个字符串按符合匹配条件的方式分割成一个字符串数组。不改变原字符串
var str="How 1are 2you 3doing 4today?";
var a=str.split(" ");
var b=str.split(" ",2);
var c=str.split(/\d/);
var d=str.split(/\d/,3);
console.log(a);//["How", "1are", "2you", "3doing", "4today?"]
console.log(b);//["How", "1are"]
console.log(c);//["How ", "are ", "you ", "doing ", "today?"]
console.log(d);//["How ", "are ", "you "]2.4、match()方法
简介:
match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配
注意: match() 方法将检索字符串 String,以找到一个或多个与 regexp 匹配的文本。这个方法的行为在很大程度上有赖于 regexp 是否具有标志 g。
如果 regexp 没有标志 g,那么 match() 方法就只能在 stringObject 中执行一次匹配,与exce的完全一致。
如果 regexp 有标志 g,它将找到全部符合正则子字符串,并返回一个数组。
如果没有找到任何匹配的文本,无论有没有g,match() 将返回 null。
没有g的正则匹配
var str="Hello45647 123 world!Hello 1423 world! ssfsdf";
var patt1=/\d+/;
var result1=str.match(patt1);
console.log(result1)
var str="Hello45647 123 world!Hello 1423 world! ssfsdf";
var patt2=/(?<hello>\d)+/;
var result2=str.match(patt2);
console.log(result2)
有g的正则匹配
var str="The rain in SPAIN stays mainly in the plain";
var n=str.match(/ain/g);
console.log(n); //["ain", "ain", "ain"]没有匹配到子字符串
var str="The rain in SPAIN stays mainly in the plain";
var n=str.match(/\d/g); //匹配数字
console.log(n); //n
在正则表达式中,i和g是两个常用的标志。除了这两个标志外,还有其他一些标志可以用于修改正则表达式的行为。
i标志(不区分大小写):使用i标志可以使匹配过程不区分大小写。例如,/abc/i将匹配"abc"、"AbC"、"ABC"等。
g标志(全局匹配):使用g标志可以进行全局匹配,即在整个字符串中查找所有匹配项,而不仅仅是第一个匹配项。例如,/abc/g将匹配字符串中的所有"abc"。
m标志(多行匹配):使用m标志可以进行多行匹配。它修改了^和$的行为,使它们匹配每一行的开头和结尾,而不仅仅是整个字符串的开头和结尾。
s标志(点号匹配所有字符):使用s标志可以使点号.匹配包括换行符在内的所有字符。默认情况下,点号.匹配除换行符外的任意字符。
u标志(Unicode匹配):使用u标志可以启用Unicode匹配模式,支持Unicode字符的匹配。
这些标志可以单独使用,也可以组合使用。例如,/abc/gi表示进行全局、不区分大小写的匹配。
请注意,标志的使用方式是在正则表达式的最后添加,例如/pattern/flags。

评论 (0)